
Introduzione
La rilevazione campionaria sui risultati economici delle aziende agricole (denominata Indagine Rica-Rea) è il risultato dell’integrazione tra l’indagine Rea condotta dall’Istituto nazionale di statistica (Istat) e la Rica (Rete di Informazione Contabile Agricola) gestita, in Italia, dall’Istituto nazionale di economia agraria (Inea). Quest’ultima è lo strumento comunitario finalizzato a conoscere la situazione economica dell'agricoltura europea e a programmare e valutare la Politica Agricola Comunitaria (Pac). Fino all’anno contabile 2002, la Rea era una rilevazione statistica campionaria su un insieme ristretto di variabili volta a stimare gli aggregati economici del settore agricolo. La Rica era invece una rilevazione su base partecipativa volontaria a carattere contabile, effettuata su un ampio insieme di variabili aziendali (molto più numeroso e dettagliato di quello osservato nella Rea) utili per le analisi microeconomiche in agricoltura, ma, nel contempo, utilizzabili per il calcolo degli stessi aggregati stimati con la Rea. L’integrazione è avvenuta a partire dall’anno contabile 2003, in seguito ad un Protocollo d’intesa stipulato tra Istat, Inea, Ministero delle Politiche agricole, alimentari e forestali, Regioni e Province autonome. Ciò ha consentito di migliorare efficienza ed efficacia dell’indagine, eliminando i possibili problemi di incoerenza dell’informazione diffusa e di eccessiva pressione statistica sulle aziende agricole, ottimizzando nel contempo le risorse disponibili.
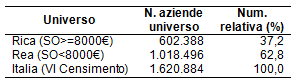
L’indagine Rica-Rea raccoglie annualmente le informazioni relative alla struttura dei costi e dei ricavi dell’azienda agricola, al costo del lavoro, ai contributi ricevuti, alle giacenze e scorte, agli acquisti e vendite di capitale fisso, al valore dei prodotti vegetali e zootecnici riutilizzati dall’azienda come mezzi di produzione nel corso dello stesso esercizio. Il campione di aziende da osservare è ottenuto dall’unione di due campioni distinti e indipendenti. In particolare, l’insieme di tutte le aziende agricole italiane1 (denotato come popolazione obiettivo o universo) è suddiviso in due sotto-insiemi complementari: le aziende piccole e le aziende medio-grandi; da ciascun sotto-insieme si procede alla selezione di un campione di aziende. La suddivisione in aziende piccole e medio-grandi è determinata dal fatto che queste ultime possono essere osservate più in dettaglio, in modo da poter soddisfare le esigenze conoscitive dettate dal regolamento comunitario. Al contrario, per le piccole, la struttura aziendale e il corrispondente regime di contabilità non consentirebbe la raccolta di informazioni così dettagliate. In occasione della rilevazione relativa all’anno contabile 2014, la popolazione obiettivo, costituita dalle aziende osservate al VI Censimento Generale dell’Agricoltura del 2010, è stata suddivisa in base al valore dello standard output (SO)2: le aziende agricole con almeno 8.000€ di SO confluiscono nell’universo Rica (aziende medio-grandi); le restanti aziende (con SO inferiore a 8.000€) confluiscono nell’universo Rea. La tabella che segue riporta le numerosità delle sub-popolazioni.
Tabella 1 - Popolazioni di riferimento per le indagini Rica e Rea
Disegno di indagine e piano di campionamento
Entrambi i campioni Rica e Rea sono selezionati, indipendentemente dal corrispondente universo, mediante campionamento probabilistico. In particolare si fa riferimento alla teoria del campionamento casuale stratificato, che prevede la suddivisione della popolazioni in strati non sovrapposti, costruiti in modo che le aziende agricole al loro interno abbiano caratteristiche simili. Da ciascuno strato si seleziona quindi, in modo completamente casuale, il campione di aziende da intervistare. La stratificazione delle aziende agricole è condotta facendo uso di informazioni provenienti dall’archivio censuario.
La strategia di stratificazione utilizzata per i due universi Rica e Rea è simile, ma con differenze nella formazione degli strati.
Il campione Rica
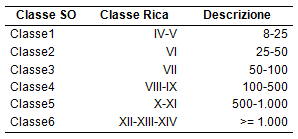
La stratificazione dell’universo Rica è condotta tenendo conto della precisione richiesta per le stime delle principali variabili di interesse e del budget disponibile, che impone di contenere l’ampiezza del campione entro certi limiti. Poiché il campione dovrebbe fornire stime accurate a livello regionale, una prima variabile di stratificazione è rappresentata dalle 21 ripartizioni territoriali ottenute considerando le regioni e le province autonome di Trento e Bolzano (al posto del Trentino-Alto Adige). Per raffinare ulteriormente la stratificazione sono state considerate altre due variabili, il livello di Standard Output e l’Orientamento Tecnico Economico (Ote3), determinate per tutte le unità dell’archivio censuario in base a procedure definite a livello europeo. Per la prima variabile sono state definite 6 classi (si veda tabella 2). L’Ote è invece una variabile categorica che classifica le aziende agricole in base, per l’appunto, al loro orientamento tecnico economico prevalente. La prima cifra dell’Ote identifica la tipologia generale dell’azienda (le nove tipologie generali sono riportate nella seconda colonna della tabella 3), le successive due cifre indicano le sotto-tipologie aziendali. Per il campione Rica, il lavoro di esperti del settore ha permesso di aggregare le possibili sotto-tipologie di Ote in classi omogenee a livello regionale (per tener conto delle peculiarità territoriali); ciò ha comportato aggregazioni diverse da regione a regione.
Tabella 2 - Classi di Standard Output delle aziende Rica (valori in migliaia di euro)
La combinazione delle tre variabili di stratificazione (regione, classi di SO e classi di Ote) ha portato ad una suddivisione dell’universo Rica in 956 strati. La determinazione dell’ampiezza complessiva del campione Rica, e la sua suddivisione (allocazione) negli strati, è stata effettuata in modo da contenere l’ampiezza complessiva del campione, tenendo allo stesso tempo conto di vincoli relativi alla precisione delle stime regionali, che lo stesso dovrebbe garantire. La procedura di determinazione dell’ampiezza complessiva del campione e della relativa allocazione negli strati sfrutta le informazioni presenti nell’archivio censuario e molto legate alle principali variabili target dell’indagine, ovvero: la Superficie Agricola Utilizzata (Sau), lo Standard Output (SO) e l’Unità Bestiame (Uba) (ottenuta come somma delle unità di bestiame delle diverse specie animali opportunamente trasformate; per l’indagine Rica-Rea si fa riferimento ad un numero ridotto di specie animali rispetto alle indicazioni fornite da Eurostat).
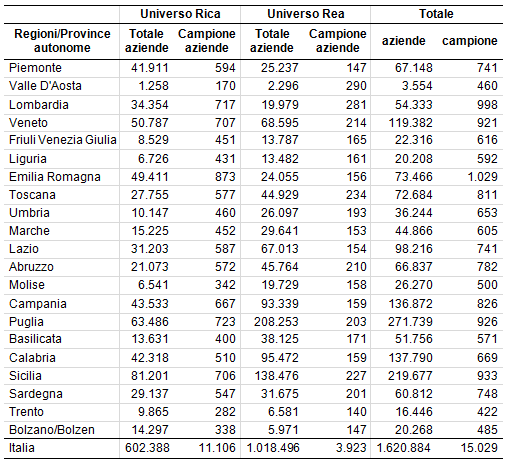
Da un punto di vista metodologico, l’ampiezza complessiva del campione Rica e la relativa allocazione tra gli strati è stata determinata utilizzando la metodologia predisposta da Bethel (1989) e implementata nel software generalizzato d’Istituto Mauss4 (nella sua versione per l’ambiente R5). L’applicazione del metodo in questione ha condotto alla definizione di un campione complessivo di 11.106 aziende agricole la cui distribuzione a livello regionale è desumibile dalla tabella 4. Il campione in questione, in assenza di mancate risposte e altri errori in fase di rilevazione, garantirebbe stime regionali molto accurate per la Sau, poiché l’errore campionario espresso in termini relativi (ottenuto rapportando l’errore campionario standard alla quantità da stimare) nella maggior parte dei casi, è al di sotto del 4% (5% programmato) con l’eccezione di Toscana, Umbria e Lazio. Tutti gli errori campionari relativi attesi per lo SO sono al di sotto del 5%, con la sola eccezione della provincia autonoma di Trento (CV pari al 5,4%). Maggiore variabilità si osserva per l’Uba che comunque presenta errore atteso al di sotto del 6%, fatta eccezione per il Friuli Venezia Giulia (6,2%). A livello complessivo il campione garantisce stime delle variabili in questione con un errore campionario relativo inferiore al 2%.
Il campione Rea
Anche il campione Rea è ottenuto facendo ricorso al campionamento casuale stratificato. Per la stratificazione dell’universo Rea sono state utilizzate le stesse variabili considerate per il campione Rica, ossia Regione, Standard Output (SO) e Orientamento Tecnico-Economico (Ote). Anche in questo caso si considerano 21 regioni (19 amministrazioni locali, cui si aggiungono le Province Autonome di Trento e Bolzano), mentre per SO e Ote sono state considerate poche grandi classi. In particolare per lo SO sono state considerate 4 classi, mentre per l’Ote i nove orientamenti tecnico-economici principali sono stati ulteriormente aggregati in tre macro-orientamenti economici come riportato in tabella 3.
Tabella 3 - Macro-orientamenti tecnico-economici (Ote) considerati per la stratificazione

La combinazione delle tre variabili di stratificazione ha determinato una ripartizione dell’universo Rea (1.018.496 aziende agricole con meno di 8.000 euro di Standard Output) in 252 strati. Questa stratificazione è stata utilizzata per determinare l’ampiezza del campione e la corrispondente allocazione tra gli strati. In particolare il campione è stato determinato in modo che, unitamente al campione Rica, garantisse delle stime dei totali per le variabili Sau, SO e Uba che, a livello regionale, fossero caratterizzate da errore campionario relativo al di sotto delle soglie introdotte precedentemente (5% o meno per la Sau, 5,5% o meno per lo SO, 6,5% o meno per l’Uba). La siffatta procedura ha condotto ad un campione di 3.923 aziende.
La tabella 4 riporta una sintesi della distribuzione dei due campioni e quindi la distribuzione complessiva del campione a livello delle 21 ripartizioni territoriali considerate.
Tabella 4 - Schema riassuntivo delle numerosità del campione complessivo e a livello regionale
La raccolta dati
La raccolta dei dati è gestita dall’Inea che si avvale delle proprie strutture regionali, dagli Uffici competenti delle Regioni e Province Autonome, da altri Enti Locali (ad es. Agenzie regionali di sviluppo agricolo) e vede la partecipazione operativa delle organizzazioni professionali agricole, degli ordini e collegi professionali agricoli e di tecnici esperti con formazione specifica in contabilità agraria.
Nella pratica, i dati sui risultati economici delle aziende agricole sono raccolti da un rilevatore, che si reca una o più volte presso l’azienda o presso il domicilio del conduttore d’azienda. Le modalità previste per la raccolta dati sono di due tipi distinti:
- per le aziende con valore di SO uguale o superiore agli 8.000 € (fino all’anno contabile 2013, la soglia faceva riferimento ad un valore pari o superiore ai 4.000 €), le informazioni vengono raccolte attraverso un software di gestione della contabilità aziendale (Gaia) sviluppato dall’Inea. Il software consente, nel corso dell’anno contabile di riferimento, la rilevazione integrata dei dati aziendali, considerando gli aspetti tecnici, economici, finanziari e patrimoniali;
- per le aziende con valore di SO inferiore agli 8,000 € e per quelle con SO maggiore di tale soglia, ma non disponibili a tenere la contabilità tramite software Gaia, l’intervista diretta al conduttore (retrospettiva) avviene, a cura di un rilevatore che registra i dati raccolti attraverso un questionario elettronico predisposto dall’Istat6.
Purtroppo, nonostante gli sforzi prima e durante la fase di raccolta dei dati, è fisiologico che non sia possibile raccogliere le informazioni per tutte le unità del campione (a causa di rifiuti, irreperibilità, ecc.). L’incidenza di tale fenomeno, noto come mancata risposta totale, nelle precedenti edizioni dell’indagine si è attestato intorno al 38%. Tale fenomeno determina una certa riduzione della precisione delle stime finali dell’indagine e, quel che è più grave, in assenza di contromisure, potrebbe introdurre distorsione nelle stime finali. Per questo motivo, in fase di elaborazione dei dati, vengono adottatati metodi opportuni che cercano di ridurre per quanto possibile l’impatto delle mancate risposte totali sulle stime (per maggiori dettagli si veda il par. relativo alle elaborazioni finali).
La fase di controllo e correzione dei dati raccolti
I questionari Rea vengono sottoposti ad una prima fase di revisione presso gli Uffici territoriali di competenza; per le aziende Rica, invece, il software Gaia prevede già al suo interno una serie di controlli di coerenza che consentono di pervenire alla stesura del bilancio aziendale, secondo lo schema civilistico oppure secondo lo schema riassuntivo predisposto dall’Inea. Tale informazione è riversata nella banca dati Rica on-line che prevede livelli di consultazione differenziati per tipologia di utente (pubblico, privato, soggetto Sistan, ecc.).
I dati sono quindi trasmessi all’Istat dove vengono sottoposti ad una ulteriore ed articolata fase di controllo e correzione volta ad individuare e trattare i valori anomali e le mancate risposte parziali (informazioni che non sono state raccolte per un qualche motivo).
In prima istanza si cerca di individuare eventuali valori errati che possono avere maggiori effetti distorsivi sulle stime finali dei parametri di interesse (solitamente rappresentati dai totali delle principali variabili economiche). L’individuazione di valori rilevanti che potrebbero risultare errati viene effettuata in due passi:
- individuazione di stime anomale mediante tecniche di macroediting;
- individuazione dei valori anomali rispetto a distribuzioni bi-variate dei dati; i valori giudicati errati vengono corretti attraverso opportuni modelli statistico-matematici.
In questa fase tutte le variabili economiche rilevate nel questionario sono sottoposte a controllo.
Individuazione dei valori anomali mediante macroediting
Nel macroediting (Barcaroli et al., 1999), non si parte dal dato elementare ma da opportune aggregazioni dei dati elementari; laddove si individuino delle aggregazioni che risultino anomale (se confrontate a opportune stime di aggregati di riferimento), si procede a una revisione manuale e/o interattiva delle sole aziende che contribuiscono maggiormente alla determinazione dell’anomalia. Siffatta procedura permette di ridurre i tempi e i costi del controllo interattivo dei dati, mantenendo entro limiti accettabili i livelli di accuratezza attesi per le stime finali.
Nel caso dell’indagine Rica-Rea, per ogni variabile sottoposta a macroediting, si confrontano le stime dei totali delle variabili osservate (a livello complessivo e per opportune ripartizioni della popolazione) con gli stessi totali ottenuti nella precedente edizione dell’indagine. Per ogni aggregato anomalo, vengono quindi analizzati i dati delle aziende che contribuiscono maggiormente alla sua determinazione. I valori ritenuti errati vengono corretti, i valori anomali che non si ritiene affetti da errore non sono modificati, ma, in alcuni casi, si procede ad una modifica del peso di indagine associato all’unità in questione, al fine di ridurne l’impatto sulle stime finali (per i dettagli sui pesi si veda il paragrafo 5).
Individuazione dei valori anomali mediante uso di rapporti
In questo caso, l’individuazione dei valori anomali viene effettuata mediante analisi grafica delle distribuzioni campionarie (a livello complessivo o per opportune ripartizioni della popolazione), dei seguenti rapporti caratteristici:
- costi totali/ricavi totali;
- spese per acquisto di beni e servizi per le coltivazioni/(ricavi per vendita di prodotti vegetali + ricavi per vendita di prodotti vegetali trasformati);
- spese per acquisto beni e servizi per allevamenti/(ricavi per vendita di animali + ricavi per vendita prodotti zootecnici + ricavi per vendita prodotti zootecnici trasformati);
- retribuzioni lorde dipendenti tempo indeterminato/ giornate di lavoro corrispondenti;
- contributi sociali dipendenti tempo indeterminato/ retribuzioni lorde corrispondenti;
- retribuzioni lorde dipendenti tempo determinato/ giornate di lavoro corrispondenti;
- contributi sociali dipendenti tempo determinato/ retribuzioni lorde corrispondenti;
I rapporti anomali rispetto ai restanti vengono selezionati per essere sottoposti a controllo manuale; i valori giudicati errati in quanto al di fuori di opportuni intervalli vengono quindi corretti.
Trattamento delle incoerenze nei dati
Una ulteriori serie di controlli sui dati raccolti riguarda la loro coerenza a livello micro, nel senso che di solito i valori di variabili osservate sulla stessa unità devono sottostare ad una serie di vincoli, determinati dalla natura stessa delle variabili (es. le somme di superfici devono essere uguali al dato fornito relativamente alla superficie totale; alcune variabili devono sottostare a vincoli di disuguaglianza ecc.). In particolare, le regole di controllo interessano le nove variabili quantitative descrittive della struttura aziendale (superfici e consistenza allevamenti) e tutte le circa 100 variabili economiche (sezioni 12-17 del questionario).
Elaborazioni finali
La fase di controllo e correzione dei dati è seguita da una fase di elaborazione che di fatto va a modificare i pesi assegnati alle aziende. In fase di estrazione del campione a ciascuna azienda viene assegnato un peso che è pari all’inverso della probabilità che l’azienda stessa entri a far parte del campione. Tale peso dovrebbe essere utilizzato in fase di stima (es. l’ammontare totale di una variabile è stimato come somma dei valori della variabile nelle unità del campione moltiplicati per il peso campionario) se in fase di raccolta dei dati non vi fossero errori di mancata osservazione, tipicamente dovuti ad errori nella lista (es. indirizzo errato) o a mancate risposte totali.
La presenza degli errori di mancata osservazione, determinando una riduzione dell’ampiezza campionaria prefissata, è suscettibile di provocare una perdita di precisione e l’introduzione di distorsione nelle stime (ciò accade quando c’è un qualche fenomeno di autoselezione di chi, una volta selezionato nel campione, decide poi di non partecipare all’indagine). Per tale motivo, prima della fase di controllo dei dati elementari, descritta nel paragrafi precedenti, si procede ad una prima correzione dei pesi volta a compensare la mancata risposta. A questa correzione dei pesi ne segue una finale, che ha l’obiettivo di aumentare la precisione delle stesse.
La possibilità di migliorare la precisione delle stime – in particolare, di ridurre la possibile distorsione derivata dalle mancate risposte – è legata alla disponibilità di informazioni ausiliarie (tipicamente variabili nell’archivio censuario, o di altre indagini importanti come quella sulla Struttura delle produzioni Agricole) che risultino legate alle variabili osservate nell’indagine e disponibili per tutta la popolazione. Lo sfruttamento di tali informazioni ausiliarie per migliorare l’accuratezza delle stime passa attraverso la specificazione di opportuni modelli statistici. Questa operazione, all’atto pratico, si configura come una ulteriore modifica dei pesi associati alle unità, detta calibrazione; essa è impostata in modo da cambiare il meno possibile i pesi di partenza, inoltre presenta il vantaggio di fornire un sistema complessivo di pesi, che, se applicato all’insieme delle variabili ausiliarie a livello dei rispondenti all’indagine, permette di riprodurre perfettamente i totali delle stesse a livello di archivio censuario.
I pesi così determinati sono quelli utilizzati per il calcolo delle stime dei principali aggregati economici diffusi normalmente dopo circa 18 mesi dal periodo di riferimento dei dati.
Le procedure di elaborazione, precedentemente descritte, permettono di produrre stime accurate per i principali aggregati economici, sia a livello nazionale che regionale. Con riferimento al dettaglio regionale, si fa presente che, in genere, l’indagine permette di stimare con una discreta accuratezza7 i valori di produzione, valore aggiunto, costo del lavoro, margine operativo lordo e risultato lordo di gestione. Laddove talune stime dovessero presentare problemi di accuratezza, l’Istat provvede alla segnalazione in sede di diffusione.
L’indagine, nel suo complesso, è progettata per diffondere stime degli aggregati di interesse, in corrispondenza di disaggregazioni pianificate inizialmente, tuttavia non consente di condurre analisi dettagliate, qualora si volesse riprodurre a livello regionale le stesse disaggregazioni impiegate per la diffusione dei risultati a livello nazionale (es. stime per classi di fatturato a livello regionale).
Conclusioni
Le procedure dell’indagine descritte nei paragrafi precedenti, sono il risultato di un lungo percorso di evoluzione e miglioramento del processo di produzione e della qualità delle statistiche diffuse per il settore agricolo. Tale percorso ha visto il coinvolgimento di diversi soggetti istituzionali e si è avvalso dell’esperienza di numerosi esperti di diversa formazione (statistici, agronomi, ecc.). Ciò ha aumentato la quantità e la qualità delle informazioni rese disponibili agli utenti; ad oggi l’utente può accedere ad una serie storica di circa 10 anni di dati con dettaglio regionale e ovviamente nazionale.
Tutti i dati sono facilmente accessibili attraverso il sistema informativo Istat dedicato all’agricoltura, consultabile al seguente indirizzo: [link].
Si sottolinea che il percorso di miglioramento è ancora oggi in atto, il principale obiettivo resta quello di migliorare la qualità delle statistiche diffuse sia a livello nazionale, ma soprattutto a livello regionale, tenendo conto delle nuove esigenze informative dell’utenza e dei cambiamenti in atto nel settore agricolo nel complesso.
Riferimenti bibliografici
-
Barcaroli G., D'Aurizio L., Luzi O., Manzari A., Pallara A. (1999), Metodi e software per il controllo e la correzione dei dati, Documenti Istat, n.1/1999
-
Bethel J. (1989), Sample Allocation in Multivariate Survey. Survey Metodology, 15, pp. 47-57
-
Guarnera U., Luzi O., Tommasi I. (2007), La nuova procedura di controllo e correzione degli errori e delle mancate risposte parziali nell'indagine sui Risultati Economici delle Aziende agricole (Rea), Documenti Istat, n. 3/2007, [link]
- 1. L’insieme delle aziende agricole prese in considerazione è quello individuato in occasione dell’ultimo Censimento generale dell’agricoltura, in questo caso si fa riferimento ai risultati del VI Censimento condotto nel 2010. La lista non include le cooperative di sola trasformazione di vino e olio che pertanto non sono osservate dalla Rica-Rea.
- 2. Lo Standard Output di una determinata produzione agricola, sia essa un prodotto vegetale o animale, è il valore monetario della produzione, che include le vendite, i reimpieghi, l’autoconsumo e i cambiamenti nello stock dei prodotti, al prezzo franco azienda (a questa regola generale di considerare i prezzi senza i costi di trasporto e commercializzazione, fanno eccezione solo i prodotti per i quali è impossibile la vendita senza il confezionamento: in questo caso il prezzo è considerato quello del prodotto confezionato). Lo SO non include i pagamenti diretti, l’imposta sul valore aggiunto e le tasse sui prodotti.
- 3. Classificazione degli indirizzi produttivi delle aziende agricole, adottata dalla Comunità europea (Reg.CE n. 1242/2008). L’indirizzo produttivo dell’azienda viene determinato sulla base dell’incidenza percentuale del valore delle varie attività produttive, rispetto allo Standard Output complessivo dell’azienda. È data dal valore dei beni e servizi ottenuti dall’azienda agricola con la propria attività “caratteristica”. Per la valutazione ai prezzi base, alla produzione sono aggiunti i contributi e sono sottratte le imposte ai prodotti. Si fa presente che l’Ote è assegnata alle sole aziende agricole che, in quanto tali, rientrano nella Sezione A della classificazione Ateco 2007.
- 4. [link]
- 5. [link]
- 6. Una stampa del questionario è disponibile al seguente indirizzo: [link]
- 7. Ad oggi la politica di diffusione dei dati in questione non prevede il rilascio a utenti esterni delle stime degli errori standard associati agli aggregati pubblicati.