
Introduzione
Le tematiche relative alla valutazione delle politiche di sviluppo rurale stanno assumendo sempre maggiore rilevanza sia in ambito accademico che istituzionale. Nuovi stimoli e forti giustificazioni ad approfondire la ricerca in questo ambito provengono, infatti, non solo dalla letteratura scientifica, ma anche da alcune indicazioni pubbliche maturate per lo più a livello europeo. Recentemente sono state sottolineate sia le complessità che si possono riscontrare nella valutazione ex-post del primo pilastro della PAC (Esposti 2011) che le principali problematiche relative alla valutazione del secondo (Salvioni, Sciulli 2011).
Questo lavoro intende portare un contributo al dibattito acceso nell’ambito della Task Force “Monitoraggio e Valutazione” della Rete Rurale Nazionale a proposito della costruzione del gruppo di controllo o controfattuale (Martini, Sisti 2009). In particolare, si pone in evidenza il ruolo che le informazioni raccolte dall’Istituto Nazionale di Economia Agraria (INEA) - attraverso la Rete d’Informazione Contabile Agricola (RICA) - potrebbero giocare nella valutazione di Programmi di Sviluppo Rurale (Cagliero et al. 2010). A tale scopo, vengono presentati i risultati di una sperimentazione effettuata attraverso l’utilizzo della fonte INEA, considerando altresì i dati amministrativi del Programma di Sviluppo Rurale 2007-2013 della Regione Veneto. Il metodo applicato è quello dello Statistical Matching con tecnica di abbinamento uno a uno. In questo caso, è stato considerato un campione di beneficiari della misura 121 estratto dalla lista della Regione Veneto (Ammodernamento aziende agricole, Bando del 2008 DGR N. 199 del 12/02/2008 e successivi, ovvero tutte le domande chiuse o finanziate - misura singola, nell’ambito dei PIF e del Pacchetto giovani), mentre il database RICA della medesima regione è stato utilizzato come bacino dal quale attingere per l’individuazione delle unità non beneficiarie. Il proposito è dunque quello di tracciare un percorso per definire il momento propedeutico alla valutazione degli effetti di un programma o di una misura in particolare.
La costruzione del gruppo di controllo attraverso i dati RICA
La RICA è indicata dalla Commissione Europea DG-Agri come possibile fonte di informazioni per la valutazione delle politiche di sviluppo rurale, pertanto, tali dati sono già stati utilizzati in passato in ambito valutativo (Cisilino 2010). In seguito alla firma del Protocollo d’intesa ISTAT-INEA del 2003, la RICA-REA ha assunto il ruolo di principale fonte di dati microeconomici relativi alle aziende agricole italiane. Tra le variabili registrate da quest’indagine si annoverano anche alcune informazioni relative alle politiche agricole, come i pagamenti derivanti dai PSR percepiti dalle aziende. Tuttavia, in generale, non è possibile affermare che la condizione di beneficiario di una misura di PSR sia una variabile rispetto alla quale la RICA possa essere considerata rappresentativa, a meno che non sia stato costruito a questo scopo uno specifico campione satellite di beneficiari (Cisilino, Zanoli 2011).
Nell’ambito delle politiche di aiuto alle imprese, le principali strategie adottabili per misurarne l’impatto sono il one-group design e il comparison-group design (Bondonio, 2000). Il primo sistema mette a confronto solo le aziende che ricevono il contributo (prima e dopo), mentre il secondo studia le differenze tra il gruppo di aziende che gode dell’intervento e quelle che, invece, ne rimangono escluse. Quest’ultimo, definito gruppo di controllo, viene utilizzato per la stima degli effetti (analisi controfattuale). Entrambi gli approcci generano distorsioni nelle stime d’impatto, tuttavia, è possibile adottare alcune metodologie che ne limitino la portata. Negli ultimi anni, per individuare il gruppo di controllo è stato ampiamente applicato il metodo dello Statistical Matching (Rubin 1973; Heckman et al. 1998). Quest’ultimo prevede di selezionare per ogni unità i-esima che beneficia degli incentivi, un’unità (o più unità a seconda della metodologia scelta) i*-esima ad essa corrispondente tra quelle escluse dal programma, con caratteristiche simili a quelle che beneficiano della politica oggetto di valutazione. Questo metodo permette di risolvere il problema del selection bias, ovvero la distorsione derivante dal fatto che la partecipazione al programma non sia casuale, ma dipenda da alcune caratteristiche dei soggetti considerati.
Il metodo è tanto più efficace quanto maggiore è la numerosità dei non beneficiari. Un’elevata numerosità dei non beneficiari permette, infatti, una scelta più ampia, dunque più accurata, per individuare le unità più simili a quelle che compongono il gruppo dei beneficiari . L’abbinamento tra unità beneficiarie e non beneficiarie viene comunemente effettuato sulla base del Propensity Score (Rosembaum e Rubin 1984), ovvero della probabilità dell’unità di entrare a far parte del programma. Il Propensity Score (PS) può essere stimato attraverso un modello logit o probit in cui la probabilità di partecipazione al programma viene fatta dipendere da un insieme di variabili considerate influenti rispetto all’inclusione e rilevate prima dell’inizio del programma stesso.
I risultati dell’abbinamento ottenuto applicando il PS devono inoltre rispettare l’ipotesi di esistenza di un supporto comune e la proprietà di bilanciamento (Heckman, et al. 1999). La prima fa riferimento al fatto che in una situazione ideale ad ogni trattato dovrebbe corrispondere un non trattato con valore di PS uguale (o molto simile). L’analisi di bilanciamento consiste invece nel verificare se per ogni valore, o intervallo, di PS le variabili di matching abbiano la stessa distribuzione per i due gruppi.
Il gruppo dei beneficiari può essere individuato utilizzando dati di fonte amministrativa , mentre il gruppo dei non beneficiari individuando successivamente un insieme di unità escluse dal programma. Ad esempio, in questo lavoro, il campione rappresentativo dei beneficiari viene estratto dal database che contiene informazioni relative a tutte le aziende che usufruiscono della misura 121 del PSR Veneto (resa disponibile dalla Regione), mentre i dati RICA vengono utilizzati proprio per la costruzione del gruppo di controllo.
Il percorso per l’individuazione dei due gruppi si basa sostanzialmente su tre passaggi:
- individuazione del campione dei beneficiari. Nel caso presentato, il data set dei beneficiari risulta composto complessivamente da 1.198 aziende (considerando tutte le articolazioni della 121). Da questo è stato estratto un campione di 164 unità, stratificando le aziende in base ad una aggregazione di OTE e UDE. Da ciascuno strato è stato estratto un numero di beneficiari proporzionale alla dimensione dello strato, con Campionamento Casuale Semplice (CCS).
- individuazione del campione dei non beneficiari. Nel caso presentato, il campione RICA 2008 viene utilizzato per la selezione del gruppo di controllo. Il database RICA è composto da 879 aziende, 38 delle quali presenti anche nel data set dei beneficiari della misura 121. Pertanto, tali aziende sono state escluse dall’analisi (per definizione di controfattuale vengono infatti considerate solo le aziende RICA non beneficiarie).
- selezione delle variabili per il matching e stima del Propensity Score. In questa fase si procede con l’analisi delle variabili a disposizione operando una selezione di queste ultime. Infatti, si ipotizza che, condizionatamente a tali variabili, l’esposizione al trattamento sia casuale. In ogni caso, risulta essenziale cercare la combinazione ottimale tra le variabili a disposizione in modo tale che sia possibile selezionare il gruppo di controllo più simile al campione di beneficiari.
Le variabili per effettuare il matching sono quelle utilizzate per la classificazione aziendale che risultano confrontabili e comuni ai due database: OTE (Orientamento Tecnico Economico), UDE (Unità di Dimensione Economica), informazioni relative al conduttore (età, livello di istruzione), alle produzioni di qualità (con certificazioni) e alla localizzazione aziendale (zona svantaggiata). La variabile età del conduttore è presente in entrambi i data set. Tuttavia, in quello amministrativo il numero di beneficiari giovani è elevato in considerazione del fatto che i bandi favorivano i giovani ed escludevano dal finanziamento i conduttori con più di 65 anni. Nel database RICA, al contrario, risultano presenti molti conduttori di età avanzata.
Inoltre, lo studio del Bando ha ispirato la costruzione di un’ulteriore variabile utilizzata per il matching denominata “strategico”: si tratta di una riclassificazione delle aziende per OTE e UDE sulla base della rilevanza attribuita ad alcuni settori da parte della regione Veneto (7 settori ritenuti strategici dal PSR: lattiero-caseario, carne, vitivinicolo, oleicolo, grandi colture, serre, ortofrutta).
Tra gli aspetti più rilevanti emersi durante l’analisi è risultata dunque di fondamentale importanza la selezione delle variabili per la costruzione del gruppo di controllo. La scelta di queste ultime dipende da molti fattori, tra i quali, per esempio, la politica che si intende valutare o l’effettiva disponibilità dei dati. In ogni caso, questa fase è essenziale per ottenere il gruppo di controllo più simile al campione dei trattati (Cisilino et al. 2011).
Principali risultati
Le elaborazioni sono state effettuate su un data set complessivo composto di 1.005 aziende (841 non trattati presenti nel database RICA e 164 trattati estratti dal data set dei beneficiari).
Nella prima specificazione del modello utilizzato per stimare il PS, le variabili utilizzate sono: strategico, diploma del conduttore forma giuridica e produzioni di qualità (con certificazione). In questo caso, 3 unità sono state escluse dal supporto comune, e, di conseguenza, dall’analisi stessa.
I valori del PS ottenuti utilizzando questa specificazione sono abbastanza bassi, sia per i beneficiari che per i non beneficiari, ma simili tra i due gruppi, ad eccezione della parte più a destra del grafico (Figura 1). Si ricorda che ad ogni rettangolo presente nella parte superiore del grafico (beneficiari) dovrebbe corrispondere un rettangolo nella parte inferiore con dimensione simile (non beneficiari). Nella parte destra del grafico si può notare come i non beneficiari siano numericamente inferiori ai beneficiari. Questa scarsità di osservazioni suggerisce di utilizzare un soggetto non beneficiario come controllo per più individui beneficiari; in altre parole, un controllo non viene assegnato unicamente ad un trattato.
Figura 1 - Propensity score ottenuto con le variabili: strategico, diploma, forma giuridica e qualità
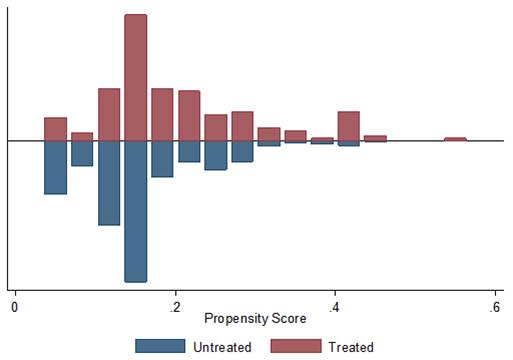
Nota: Untreated = non beneficiari (RICA), Treated = beneficiari (dataset regionale)
Fonte: elaborazioni INEA su dati RICA e data set PSR – Veneto
I risultati di una seconda specificazione del PS, in cui è stata inserita la variabile età del conduttore all’interno del set di variabili precedentemente considerate, hanno determinato l’esclusione dal supporto comune di 304 aziende. L’età del conduttore, che non può essere superiore a 65 anni per i beneficiari, è infatti piuttosto elevata per i non beneficiari. Utilizzando questa specificazione, tra l’altro, il PS è sensibilmente aumentato, soprattutto per i beneficiari (Figura 2). Si tratta quindi di una variabile importante da tenere in considerazione.
Figura 2 - Propensity score ottenuto con le variabili: strategico, diploma, forma giuridica, qualità ed età

Nota: Untreated = non beneficiari (RICA), Treated = beneficiari (dataset regionale)
Fonte: elaborazioni INEA su dati RICA e data set PSR – Veneto
In entrambe le specificazioni è stato riscontrato un numero di non beneficiari con PS elevato minore rispetto al numero di beneficiari. Gli effetti negativi di questa situazione - piuttosto frequente in analisi di questo tipo - che costringerebbero ad abbinare un trattato con un non trattato avente PS basso, possono essere fortemente attenuati, selezionando il metodo di abbinamento che meglio si adatta ai dati, ad esempio preferendo tecniche di abbinamento uno a molti, le quali prevedono di abbinare ad un trattato più di un non trattato (Dehejia e Wahba 2002). Inoltre, informazioni relative alla struttura finanziaria e patrimoniale dei beneficiari, potrebbero fornire indicazioni utili rispetto alla propensione a partecipare al programma ed essere quindi elementi importanti ai fini di un miglioramento nella stima del PS. Tuttavia, è necessario constatare che tali informazioni, presenti nella banca dati RICA, non sono invece contenute nel data set amministrativo della regione. Inoltre, si rilevano alcune differenze nella definizione delle variabili che influiscono sul loro grado di confrontabilità. Alcune sono risultate perfettamente coincidenti come, per esempio, la forma giuridica e la localizzazione territoriale in relazione alle zone svantaggiate, la presenza di contoterzismo e agriturismo. Da sottolineare, invece, le definizioni disallineate per le variabili relative alla “qualità” e al titolo di studio del conduttore, per le quali sono state quindi effettuate delle approssimazioni.
Riflessioni
I risultati mostrano che l’utilizzo della RICA per la costruzione del controfattuale si presenta come una reale possibilità, ma anche che è necessaria cautela nella selezione delle variabili da utilizzare per la stima del PS e quindi per l’inclusione delle aziende RICA nel gruppo di controllo.
Si sottolinea, infatti, che i due data set non sono stati costruiti per fini valutativi: questa consapevolezza dovrebbe permettere di analizzare in modo appropriato alcuni limiti e, se necessario, procedere con l’inserimento di proxy o di variabili di lettura - come nel caso della variabile “strategico”: si tratta di “variabili di costruzione” (non disponibili in forma diretta) che vengono create per aumentare la capacità esplicativa del database.
I risultati della sperimentazione qui presentata permettono di formulare alcune considerazioni. In particolare, sono emerse alcune criticità, tra le quali: a) l’esistenza di un problema relativo alle informazioni disponibili per il matching: quelle rilevate dalla regione sono scarse o non si sovrappongono facilmente a quelle raccolte dalla RICA; b) una differenza nella definizione delle variabili tra i due database che ha portato ad adottare alcune approssimazioni ne caso delle variabili utilizzate per il matching; c) la necessità di scegliere abbinamenti tra le unità del tipo uno a molti o valori medi di strato per sopperire alla bassa numerosità di non trattati con valore di Propensity Score elevato; d) la necessità di poter disporre di informazioni non solo strutturali, ma anche di tipo finanziario/patrimoniale relative ai beneficiari.
Tra gli ulteriori sviluppi di questo lavoro si prevede di utilizzare “tecniche di abbinamento uno a molti” al fine di evidenziare le potenzialità di questa scelta nel caso in cui il gruppo di controllo realmente confrontabile sia numericamente esiguo.
Il problema della qualità, della disponibilità e della confrontabilità di dati per la valutazione delle politiche non riguarda certo soltanto l’ambito agricolo (Rettore et al. 2002). Tuttavia, in questo contesto, appare necessario ipotizzare fin dalle prime fasi di programmazione una maggiore attenzione all’integrazione e all’armonizzazione delle informazioni attraverso la collaborazione dei diversi soggetti coinvolti. Inoltre, la possibilità di disporre di dati affidabili e confrontabili è condizione di base necessaria per poter testare metodologie diverse ed evitare di affidarsi ad un unico approccio. Le sperimentazioni in questo campo possono contribuire ad evidenziare le tante problematiche ancora esistenti e a suggerire nuovi percorsi di miglioramento.
Riferimenti bibliografici
-
Bondonio D. (2000), “Statistical methods to evaluate geographically-targeted economic development programs”, Statistica Applicata, vol. 12, n. 2, pp. 177-204
-
Cagliero R. , Cisilino F., Scardera A. (2010), L’utilizzo della RICA per la valutazione di programmi di sviluppo rurale, Rete Rurale Nazionale 2007-2013, Ministero delle politiche agricole alimentari e forestali
-
Cisilino F. (2010), “La valutazione delle politiche locali” in Bassi I., Cisilino F. (a cura di) I dati RICA per la valutazione di piani e programmi di Sviluppo rurale: il caso del PSR del Friuli Venezia Giulia 2000-2006, Analisi Regionali, INEA, Roma
-
Cisilino F., Zanoli A. (2011), “Principali metodi statistici per l'analisi d'impatto: il ruolo della RICA e del campione satellite”, Lavoro presentato alla Conferenza della Rete Rurale Nazionale “La RICA come strumento per la valutazione”. Roma 29 marzo 2011
-
Cisilino F., Zanoli A., Bodini A. (2011), “L’analisi d’impatto dei Programmi di Sviluppo Rurale: il ruolo della RICA per il controfattuale”, Pre-atti XLVIII Convegno SIDEA, Udine 29 – 30 Settembre 2011
-
DGR N. 199 del 12/02/2008, Programma di sviluppo rurale per il Veneto 2007-2013. Apertura termini del primo bando generale di presentazione delle domande. Condizioni e modalità per l’accesso ai benefici
-
Dehejia R.H., Wahba S. (2002), “Propensity Score-Matching Methods for Non experimental Causal Studies”, Review of Economics and Statistics 84, 151-161
-
Esposti R. (2011), “La chiave e la luce: perché valutare la riforma del primo pilastro della PAC è difficile”, Agriregionieuropa 7(25)
-
Heckman J.J., Ichimura H., Todd P. (1998), “Matching As An Econometric Evaluation Estimator”, The Review of Economic Studies 65, 261-294
-
Heckman J.J., LaLonde R.J. and Smith J.A. (1999), “The Economics and Econometrics of Active Labor Market Programs”, in Ashenfelter O., Card D. (a cura di), Handbook of Labour Economics, 1865-2097. North-Holland, Amsterdam
-
Martini A., Sisti M. (2009), Valutare il successo delle politiche pubbliche, Il Mulino
-
Programma di Sviluppo Rurale 2007-2013 Regione Veneto. Approvato con Decisione C(2007) 4682 del 17/10/2007 della Commissione
-
Rettore E., Trivellato U., Martini A. (2002), La valutazione delle politiche del lavoro in presenza di selezione: migliorare la teoria, i metodi o i dati? - WP Dipartimento di Scienze Statistiche, Università di Padova, Dipartimento di Politiche Pubbliche e Scelte Collettive, Università del Piemonte orientale
-
Rosenbaum P.R., Rubin D.B. (1984), “Reducing bias in observational studies using sub-classification on the propensity score”, Journal of the American Statistical Association 79, 516-524
-
Rubin D.B. (1973), “The use of matched sampling and regression adjustment to remove bias in observational studies”, Biometrics 29, 185-203
-
Salvioni C., Sciulli D. (2011), “La valutazione del 2° pilastro: la luce e la chiave” Agriregionieuropa 7(26)